

Table of Contents
Chat Bots have evolved from rule-based to AI-driven and now to LLM-trained GenAI Chatbots. Rule-based ones follow predefined guidelines, using a decision-tree framework, limiting responses to configured rules. AI chatbots interpret user intent, extracting details for accurate responses. They employ advanced algorithms and knowledge databases for context-aware replies. However, their responses are confined to pre-defined intents, hindering adaptability when faced with unfamiliar queries. LLM-trained GenAI Chatbots represent the latest leap, aiming for enhanced comprehension and flexibility in addressing user needs, marking a significant advancement in the evolution of conversational AI.
LLM-trained GenAI chatbots represent a cutting-edge development in chatbot technology, employing NLP and deep learning to deliver highly conversational and tailored interactions. These ‘intent-less’ GenAI-powered chatbots differ from traditional ones, as they generate context-aware and precise responses based on user input rather than relying on predefined intents and responses. Besides context-aware responses, the speed of deployment is a major advantage over traditional ones. However, a lot depends on the type of data – structured or unstructured – that the GenAI is expected to refer while responding to users’ queries.
GenAI Chatbots based on Structured Data
When data is structured (for example, CRM / ERP data on customer orders, revenue, profitability, etc.), there is no specific data preparation required. Usual best practices for data preparation are required to ensure data is properly labelled and indexed. Thereafter, model training is nothing but optimizing the way LLM responses to users’ questions in natural language. This is basically making sure prompts are designed appropriately to allow the LLM to get the right information from the indexed database. See below section on prompt engineering.
GenAI Chatbots based on Unstructured Data
When it comes to unstructured data (for example text in pdf, docs, websites, etc) data preparation / training can happen using two ways a) Supervised Fine-tuning using question-answer pairs; and b) RAG or Retrieval-Augmented Generation technique.
- RAG Technique: Instead of expecting the LLM to know everything, RAG allows it to pull information from an external database when required. LLMs perform remarkably well in natural language applications like text summarization, extracting relevant information, or even converting natural language into database queries or scripting code. To train an LLM on unstructured data using RAG, one would need to first identify the relevant sources of knowledge. These sources could include databases, websites, or other text. Once these sources have been identified, they can be indexed and searched using an information retrieval system. The retrieval augmented approach uses the LLM to generate an answer based on the additionally provided relevant info from your data source. Therefore, you don’t rely on internal knowledge of the LLM to produce answers. Instead, the LLM is used only for extracting relevant information from documents you passed in and summarizing it.
We don’t see any reasons why the question-answer pair approach needs to be followed for all unstructured data when RAG can deliver similar results much faster and at significantly lower cost. However, if the data is very specific to a particular industry and if some of the terms are not already part of the LLM’s vocabulary, then we follow a hybrid approach of fine-tuning the model for those specific terms and using RAG for rest. In this blog post, we explore the RAG technique further.
Enterprise Data Flow in LLM-based Solution using RAG
The picture below depicts a simplified flow of data in an LLM-based chatbot solution using RAG technique. The first step is to convert text from multiple sources into a large, scored vector, which can be efficiently compared to other scored vectors to assist with recommendation, classification, and search tasks.
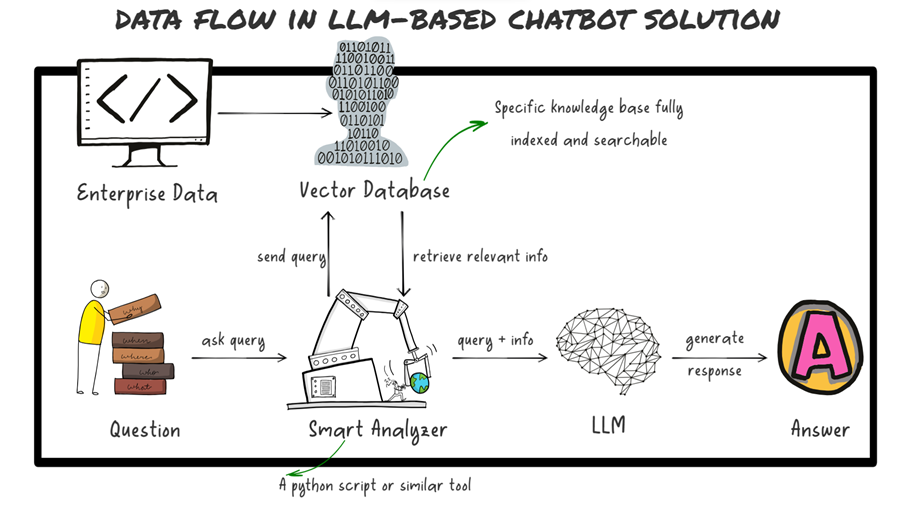
When a user submits a question, a ‘smart analyser’ generates another vector – this time, of the user’s text – that is then compared to the full set of precomputed vectors to identify one or more relevant text chunks. The analyser retrieves relevant matching data based on relevant text chunks identified and augments the retrieved relevant data with context in the prompt before sending it to the LLM. Finally, the combined prompt is sent to the LLM, which then generates an answer and passes it along to the user.
Data Preparation
No matter how simple the above data flow looks like, it is a complicated process of gathering large quantities of structured and unstructured data, preprocessing it, and preparing it for training the LLM to give right responses to users’ queries. Let’s delve deeper into steps involved in data preparation for large language models.
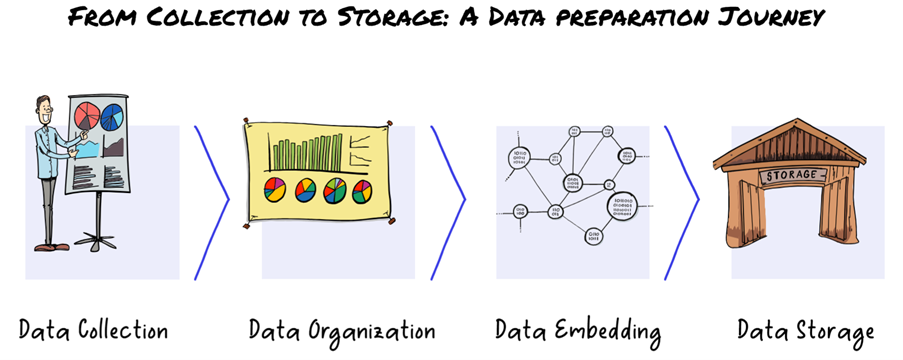
- Data Collection: The first step in the data preparation process is to collect data relevant to the task the LLM needs to be trained for. Once you have figured out what types of data are needed to train the LLM for your use case, you need to start gathering the data. For example, if the LLM is being trained to answer customers queries on retail products and their orders, the data collected should include not only product catalogues, their features, prices, and customer reviews but also all historical customer order data. The required data needs to be collected from various sources such as the web, social media, text or pdf documents, ERP / CRM databases, etc. You may use different tools for collecting data from different sources. For simple website data, you may use a web crawler or even rely on Google Index, which is a database of all webpages the search engine has crawled to use in search results. For more complex data sources, you can use LangChain that can load data from a wide variety of sources.
- Data Organization: Once you have collected the data required to train the LLM, the next step is to preprocess and organize the data in a format that is useful for LLM. This involves a number of sub-steps including data cleaning, normalization and most importantly, tokenization. Before we get to tokenization, it is important to clean the data by removing duplicates, adding missing values, fixing incorrect values, and removing any outliers. It is equally important to convert the data into standard format and normalize it by removing special characters such as symbols, punctuation marks, etc. Tokenization is the most important task in data organizing and it involves breaking down data or text into smaller units such as individual words or phrases that will make it easier for the LLM to understand its overall meaning. For example, the sentence ‘Ingroup is your one-stop shop for CX consulting’ can be tokenized by word as follows [‘Ingroup’, ‘is’, ‘your’, ‘one-stop’, ‘shop’, ‘for’, ‘CX’, ‘consulting’]. There are different tools used for tokenization including LangChain’s text splitter module. Many practitioners use larger text chunks as part of the tokenization process, but you need to experiment to find the optimal size for your use case. However, do remember that every LLM has a token limit while receiving a prompt – for example, GPT 3.5 has a limit of 4000 tokens per prompt. Since you’ll be inserting the relevant text blocks into your prompt, you need to keep text chunks small enough to make sure that the entire prompt is no larger than 4000 tokens.
- Data Embedding: The next step is to convert text chunks that are in human language into digital form that makes it easier for LLMs to understand. Embeddings represent text in your dataset as a vector of numbers that enables LLMs to capture the meaning of your text and their relationship with each other. For example, since ‘bread’, ‘butter’ and ‘breakfast’ are often used in the same context, embedding model would compare these text chunks with each other and even score similarity as opposed to ‘butter’ and ‘cutter’ that sound similar but rarely used together. When you represent the text chunks and the user’s question as vectors, you can explore various possibilities including determining similarity between two data points and their proximity to each other. This allow LLMs to remain contextual and understand the user’s real intent without the need for an explicit statement.
- Data Storage: Once the data has been pre-processed, organized and embeddings have been created, the question is where you store these embeddings and how do you make it easily accessible by the LLM? The answer is Vector Databases. A vector is an array of numbers representing complex data types such as text, images, voice, and even structured data. Vector databases have advanced indexing and search capabilities that make them particularly useful for searching and matching data items most similar to a given item. That makes vector databases ideal for GenAI-based applications. Pinecone is one of the most popular vector databases that is used for machine learning applications.
LLM Training or Prompt Engineering
Once you have collected the relevant data, cleaned it, normalized it, broken it down into smaller text chunks and converted it into a vector format that potentially the LLM can understand, you can then test whether your model is capable of answering questions based on this database. To achieve this, you need to build prompts in a way that clearly instructs the model what you expect it to do. For example, if you would like to implement a GenAI solution that extracts data from a knowledge base and responds to users queries like a chatbot, you can add the following instruction to the prompt –
“You are an AI Assistant that help answer users’ queries based on the provided knowledge database. Answer all questions using only the context provided in this database. If you’re unsure and the answer isn’t explicitly available in the database, say “Sorry, I’m trained to answer queries related to the knowledge database only and won’t be able to help you with your query.”
By doing this, you ensure that the LLM can only answer queries that are based on the data you have in your database. This way, you can show the references GenAI used to create the response, which is important for accountability and credibility. Also, it will help you avoid giving inaccurate information.
In prompt engineering, a crucial factor is configuring the ‘temperature’ parameter, influencing the creativity of a Language Model (LLM). Higher temperatures encourage adventurous word choices with lower probabilities, fostering creativity. Conversely, lower temperatures constrain options, prompting the model to select more probable words, yielding predictable and less creative text. Crafting effective prompts involves guiding the model on conversation initiation, managing user dissatisfaction, specifying actions to avoid, and determining when to conclude. Experimentation and fine-tuning are essential to discover optimal configurations tailored to your use case, allowing you to harness the full potential of LLMs for your specific needs.
At Ingroup Consulting, we are passionate about helping businesses transform their customer experience by leveraging GenAI capabilities. We have developed a few LLM-based chatbots demonstrating examples of live use cases. If you are interested in learning more about these demo use cases, reach out to us at info@ingroupconsult.com
Images created using Drawify.